标准unix/linux下的grep通过下面參数控制上下文
grep -C 5 foo filename # 显示filename文件里匹配foo字串那行以及上下5行
grep -B 5 foo filename # 显示foo及前5行
grep -A 5 foo filename # 显示foo及后5行
标准unix/linux下的grep通过下面參数控制上下文
grep -C 5 foo filename # 显示filename文件里匹配foo字串那行以及上下5行
grep -B 5 foo filename # 显示foo及前5行
grep -A 5 foo filename # 显示foo及后5行
首先执行php -m 查看自己已安装的扩展包,避免重复安装
1.安装zip,需要先安装libzip扩展
2.安装libzip,需要先安装cmake
1.由于安装cmake十分缓慢,建议科学上网,不具备条件的同学,这里,我已经下载好了,需要的同学自取
有条件的同学可以直接服务器下载
wget https://cmake.org/files/v3.3/cmake-3.3.2.tar.gz
对应的版本可以自己去查看
2.tar xzvf cmake-3.3.2.tar.gz 解压源码包
3.安装gcc等程序包(安装过则忽略) yum install gcc-c++
4.安装cmake,先进入解压后的cmake目录,cd cmake-3.3.2, ./bootstrap
5.编译安装make && make install
6.查看版本:cmake --version,出现版本信息表示安装成功
#####第二步,安装libzip,由于cmake的限制,libzip版本必须>=0.11,具体可看官方:https://nih.at/libzip/index.html
1.#下载
wget https://nih.at/libzip/libzip-1.2.0.tar.gz
#需要高版本的同学可以去https://nih.at/libzip自己寻找
2.#解压
tar -zxvf libzip-1.2.0.tar.gz
#进入目录
cd libzip-1.2.0
3.#配置编译安装
./configure,make && make install
1.#下载
wget http://pecl.php.net/get/zip-1.16.0.tgz,#需要高版本的到官网查询[http://pecl.php.net/package/zip](http://pecl.php.net/package/zip)
2.#解压并进入目录
tar zxvf zip-1.16.0.tgz,cd zip-1.16.0
3.#编译安装/
usr/local/php/bin/phpize,
./configure --with-php-config=/usr/local/php/bin/php-config
make && make install
4.#修改php.ini,加上扩展
[zip] extension=zip.so,zlib.output_compression = On,
5.重启PHP,查看phpinfo,zip扩展已经安装成功
system libzip must be upgraded to version >= 0.11
首先,卸载系统自带的libzip
yum -y remove libzip-devel
然后从官网下载并编译安装
wget https://libzip.org/download/libzip-1.3.2.tar.gz
tar xvf libzip-1.3.2.tar.gz
cd libzip-1.3.2
./configure
make && make install
如果是下载1.5.*以上版本,则需要采用如下安装方式
yum -y install cmake
wget https://libzip.org/download/libzip-1.5.1.tar.gz
tar -zxvf libzip-1.5.1.tar.gz
cd libzip-1.5.1
mkdir build
cd build
cmake ..
make && make install
然后再安装zip发现即使在国外节点的服务器,阿里云的centos镜像源速度仍然是不讲道理的下载速度,对比原来的centos官方的源的速度,快N倍。
果断换掉破自行车,换飞机。
删除centos官方源前,请确保已经安装了wget命令,如果已经删源了还没安装wget,可以先恢复官方源,安装wget再删除官方源。
centos-release-7-7.1908.0.el7.centos.x86_64.rpm相应版本号改成你在官网看到的版本号即可风险背景
随着网络安全形势日益严峻,国家监管政策亦日趋严格。如今各企业单位申请域名开办网站之前,须依照《互联网信息服务管理办法》的规定,以企业或个人真实信息向当地通信管理局进行ICP域名备案。不少企业使用一段时间后停办网站且不再向域名经销商缴纳域名使用费,以为该域名从此即与己无关。但他们却忽视了重要法律风险——若未向通信管理局申请注销附在域名ICP备案信息,导致域名所有权变更为他人,但备案信息还是自己的对外状态,而在后续的域名流转过程中,该域名极有可能被他人购得而非法利用,从而为企业招致较大的法律风险。
在北京知识产权法院审结的(2021)京73民终1171号北京某公司诉北京某知识产权代理有限公司侵害作品信息网络传播权纠纷民事一案中,被告北京某知识产权代理有限公司正是由于域名到期停用后未及时注销ICP备案登记,导致后续域名流转至案外人王某时备案主体仍显示为被告北京某知识产权代理有限公司。在此种情形下,涉案域名网站被“改造”成某电影网,免费提供各类电影在线播放及下载服务。权利人以该网站的ICP备案主体为被告诉至法院,法院最终认定被告北京某知识产权代理有限公司侵权成立,令其赔偿原告北京某公司20000余元。除此案外,该案被告北京某知识产权代理有限公司同时遭遇其他权利人发起的多起类似诉讼,均被法院判赔数万元,并承担了诉讼费及相关支出,付出了巨大的时间和精力,累计损失不可谓不大。
那么,应当如何化解企业在域名停用后未注销ICP备案引发的法律风险呢?
近日,上海锦天城(重庆)律师事务所合伙人李章虎律师团队办理的一起北京某公司诉重庆某公司侵犯作品信息网络传播权纠纷案在重庆两江新区人民法院开庭审理,本案中李章虎律师团队代理被告重庆某公司参与案件诉讼,该案的应诉策略及诉讼思路对于企业预防此类法律风险,以及律师同仁代理此类案件时的诉讼策略选择具有十分典型的参考意义。
案情简介
原告北京某公司称其从著作权人处以独占许可的方式获得了涉案数部作品的信息网络传播权及维权权利,在授权有效期间内发现某网站正在提供涉案作品的在线播放服务,而该网站的ICP备案主体正是被告。因此,原告认为被告侵犯了其作品的信息网络传播权,故提起本次诉讼,要求被告停止侵权,赔偿经济损失及合理维权费用共计十六万元。
承办过程
本案被告重庆某公司委托上海锦天城(重庆)律师事务所合伙人李章虎律师、王艳实习律师、高宇律师助理组成律师团队参与案件诉讼。律师团队接受本次代理后,第一时间制定了诉讼策略,并协助当事人应对本次诉讼。
一般而言,作品信息网络传播权纠纷案件中被告拥有多个抗辩点,包括原被告主体不适格抗辩、无作品权利基础抗辩、不侵权抗辩以及合法来源抗辩等。在本案中,被告先前使用的涉案域名因到期后未再续费,实际上已失去对域名的管理权,但由于涉案域名ICP备案信息未申请注销,工信部查询系统显示的域名管理人仍为被告。经调查了解,确认被告确实无实施侵犯原告作品信息网络传播权的行为后,律师团队从尊重案件事实、维护当事人合法权益的角度出发,确定以“被告非案件适格主体”进行抗辩,并及时协助当事人采取以下措施:
1、 立即向当地通信管理局申请注销ICP备案;
2、 立即在当地的公安局报案,获取书面报案回执,进行自救性备案;
3、 通过Whois系统查询涉案域名的管理商,并向涉案域名管理商发函询问,核实域名情况,并敦促其尽快关停涉案网站并披露侵权期间域名的实际使用人信息;
4、 请求人民法院从涉案域名管理商处调取相关证据以明确实际侵权人。
通过采取上述取证、固证措施,律师团队在明确涉案域名销售管理商信息后积极与其联系,并努力说服且提请法院向域名销售管理商调取涉案域名的流转、使用记录,从而获得足以确定本案实际侵权人的直接证据,排除了被告重庆某公司作为ICP备案主体的侵权可能。原告自觉其诉讼请求已丧失事实依据,遂撤诉结案。
李章虎律师团队基于该案件的处理结果认为:企业在处理类似问题引发的诉讼案件中,应当于案件初始阶段就从各种途径对案件证据进行补强,若决定从“非案件适格被告”的角度进行抗辩,则必须从多个方面调查证据、固定证据,以证明自己非实际侵权主体,且最好能够举证证明确实存在其他实际侵权人。
本案中,李章虎律师团队在查阅既往的司法判例后,深知许多被控侵权的被告正是由于未能举示充分证据证明实际侵权人的存在,而被法院判决承担赔偿责任。为应对这一诉讼风险,律师团队尽最大的努力搜集相关证据,最终证明了涉案域名到期后已发生两次转移,且侵权行为发生时涉案域名已由案外人控制的关键事实,同时结合被告掌握的其他证据,形成了一个完整的证据链条,得以证明本案被告并未实施任何侵权行为,并使得法官产生内心确信,取得了极好的诉讼效果。
庭审其他重点
虽然此类案件中确定的主要抗辩点为被告主体不适格,但除此之外,在庭审中亦不能忽视对原告权属、侵权事实等方面证据的核实。因此,被告仍应当注意以下重点:
1、 审查原告主张权利作品的原始载体、权属证据是否完备;
2、 审查原告主张权利作品权利授权链条是否完整,尤其注意作品授权书的内容是否存在矛盾之处;
3、在权利作品与侵权作品之间进行认真比对,审查二者是否构成相同或实质性相似;
4、审查核对原告提供的证据原件与复印件是否一致等;
案件启示
随着互联网经济的不断发展,此类案件近年来频频发生,许多企事业单位因此遭遇“无妄之灾”,大多败诉结案。为避免陷入诉累,企业应当注意以下几点:
1、 域名不使用后,若未注销ICP备案的,必须及时向备案机关申请注销ICP备案,从源头上消除诉讼风险;
2、若未注销备案而遭遇侵权诉讼后,应当及时采取相关措施维护自身权利,包括但不限于:(1)积极向当地公安局报案,说明事实情况,获取书面报案回执;(2)通过Whois系统查询涉案域名的管理商,并向涉案域名管理商发函询问,核实域名情况,并敦促其尽快关停涉案网站并披露侵权期间域名的实际使用人信息;(3)请求法院向涉案域名管理商处调取相关证据以明确实际侵权人。
composer1 升级到composer2命令 yum Centos7
composer self-update –2
Web 开发中需要的静态文件有:CSS、JS、字体、图片,可以通过web框架进行访问,但是效率不是最优的。
Nginx 对于处理静态文件的效率要远高于 Web 框架,因为可以使用 gzip 压缩协议,减小静态文件的体积加快静态文件的加载速度、开启缓存和超时时间减少请求静态文件次数。
下面就介绍如何通过 Nginx 管理静态文件的访问,优化网站的访问速度。
配置介绍和参数如下,建议使用时删掉注释。
gzip on;
#该指令用于开启或关闭gzip模块(on/off)
gzip_buffers 16 8k;
#设置系统获取几个单位的缓存用于存储gzip的压缩结果数据流。16 8k代表以8k为单位,安装原始数据大小以8k为单位的16倍申请内存
gzip_comp_level 6;
#gzip压缩比,数值范围是1-9,1压缩比最小但处理速度最快,9压缩比最大但处理速度最慢
gzip_http_version 1.1;
#识别http的协议版本
gzip_min_length 256;
#设置允许压缩的页面最小字节数,页面字节数从header头得content-length中进行获取。默认值是0,不管页面多大都压缩。这里我设置了为256
gzip_proxied any;
#这里设置无论header头是怎么样,都是无条件启用压缩
gzip_vary on;
#在http header中添加Vary: Accept-Encoding ,给代理服务器用的
gzip_types
text/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xml
text/javascript application/javascript application/x-javascript
text/x-json application/json application/x-web-app-manifest+json
text/css text/plain text/x-component
font/opentype font/ttf application/x-font-ttf application/vnd.ms-fontobject
image/x-icon;
#进行压缩的文件类型,这里特别添加了对字体的文件类型
gzip_disable "MSIE [1-6]\.(?!.*SV1)";
#禁用IE 6 gzip
修改 /etc/nginx/mime.types 文件,增加需要压缩的文件对应 type 到上述 gzip 配置中。下面几乎涵盖了所有静态文件对应的类型:
types {
application/atom+xml atom;
application/dart dart;
application/gzip gz;
application/java-archive jar war ear;
application/javascript js jsonp;
application/json json;
application/owl+xml owl owx;
application/pdf pdf;
application/postscript ai eps ps;
application/rdf+xml rdf;
application/rss+xml rss;
application/vnd.ms-fontobject eot;
application/x-7z-compressed 7z;
application/x-bittorrent torrent;
application/x-chrome-extension crx;
application/x-font-otf otf;
application/x-font-ttf ttc ttf;
application/x-font-woff woff;
application/x-opera-extension oex;
application/x-rar-compressed rar;
application/x-shockwave-flash swf;
application/x-web-app-manifest+json webapp;
application/x-x509-ca-cert crt der pem;
application/x-xpinstall xpi;
application/xhtml+xml xhtml;
application/xml xml;
application/xml-dtd dtd;
application/zip zip;
audio/midi kar mid midi;
audio/mp4 aac f4a f4b m4a;
audio/mpeg mp3;
audio/ogg oga ogg;
audio/vnd.wave wav;
audio/x-flac flac;
audio/x-realaudio ra;
image/bmp bmp;
image/gif gif;
image/jpeg jpe jpeg jpg;
image/png png;
image/svg+xml svg svgz;
image/tiff tif tiff;
image/webp webp;
image/x-icon cur ico;
text/cache-manifest appcache manifest;
text/css css less;
text/csv csv;
text/html htm html shtml;
text/mathml mml;
text/plain txt;
text/rtf rtf;
text/vcard vcf;
text/vtt vtt;
text/x-component htc;
text/x-markdown md;
video/3gpp 3gp 3gpp;
video/avi avi;
video/mp4 f4p f4v m4v mp4;
video/mpeg mpeg mpg;
video/ogg ogv;
video/quicktime mov;
video/webm webm;
video/x-flv flv;
video/x-matroska mkv;
video/x-ms-wmv wmv;
}
通过设置Expires,开启缓存。
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf|flv|ico)$ {
expires 30d;
access_log off;
}
location ~ .*\.(eot|ttf|otf|woff|svg)$ {
expires 30d;
access_log off;
}
location ~ .*\.(js|css)?$ {
expires 7d;
access_log off;
}
1. 根据 IP 访问频率封禁 IP
2. 设置账号登陆时长,账号访问过多封禁 设置账号的登录限制,只有登录才能展现内容 设置账号登录的时长,时间一到则自动退出
3. 弹出数字验证码和图片确认验证码 爬虫访问次数过多,弹出验证码要求输入
4. 对 API 接口的限制 每天限制一个登录账户后端 api 接口的调用次数 对后台 api 返回信息进行加密处理
因为user-agent带有Bytespider爬虫标记,这可以通过Nginx规则来限定流氓爬虫的访问,直接返回403错误。 修改对应站点配置文件(注意是在server里面)
添加红色部分
server {
listen 80 default_server;
listen [::]:80 default_server;
index index.html index.htm index.nginx-debian.html;
server_name _;
location / {
try_files $uri $uri/ =404;
}
#forbidden Scrapy
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#forbidden UA
if ($http_user_agent ~ "Bytespider|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|python-requests|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
#forbidden not GET|HEAD|POST method access
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
}
FeedDemon 内容采集 BOT/0.1 (BOT for JCE) sql注入 CrawlDaddy sql注入 Java 内容采集 Jullo 内容采集 Feedly 内容采集 UniversalFeedParser 内容采集 ApacheBench cc攻击器 Swiftbot 无用爬虫 YandexBot 无用爬虫 AhrefsBot 无用爬虫 YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!) jikeSpider 无用爬虫 MJ12bot 无用爬虫 ZmEu phpmyadmin 漏洞扫描 WinHttp 采集cc攻击 EasouSpider 无用爬虫 HttpClient tcp攻击 Microsoft URL Control 扫描 YYSpider 无用爬虫 jaunty wordpress爆破扫描器 oBot 无用爬虫 Python-urllib 内容采集 Python-requests 内容采集 Indy Library 扫描 FlightDeckReports Bot 无用爬虫 Linguee Bot 无用爬虫 使用python验证
使用requests模块
import requests
# 最基本的不带参数的get请求
r = requests.get('http://192.168.28.229')
print(r.content)
使用urllib模块
import urllib.request
response = urllib.request.urlopen('http://192.168.28.229/')
print(response.read().decode('utf-8'))
返回403就表示起作用了。
b'<html>\r\n<head><title>403 Forbidden</title></head>\r\n<body>\r\n<center><h1>403 Forbidden</h1></center>\r\n<hr><center>nginx</center>\r\n</body>\r\n</html>\r\n'

robots是网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。
注意:它只是做了协议规定,是否允许将爬取的数据收录,不影响网页访问。
备注:对于手动写爬虫技术人员而言,一般都是直接忽略掉的。
如果不允许所有的爬虫蜘蛛访问,内容如下:
User-agent: * Disallow: /
因为user-agent带有Bytespider爬虫标记,这可以通过Nginx规则来限定流氓爬虫的访问,直接返回403错误。
具体操作,请查看上面的nginx配置。
备注:这样可以防止一部分爬虫访问,以及初级爬虫人员。
有些网站,你从浏览器可以打开正常的页面,而在requests里面却被要求输入验证码或者是重定向到其他的页面。 原理:当点击登录时,触发js加密代码,复杂的加密算法参数+时间戳+sig值,后台进行 参数+时间的限制。验证成功后,才可以登录。
备注:爬虫高手需要模拟浏览器行为,加载js代码以及图片识别,才能正常登陆。
1. 根据 IP 访问频率封禁 IP(注意:频率要控制好,否则容易误伤。) 2. 设置账号登陆时长,账号访问过多封禁。 设置账号的登录限制,只有登录才能展现内容 设置账号登录的时长,时间一到则自动退出 3.弹出数字验证码和图片确认验证码 爬虫访问次数过多,前端弹出验证码要求输入 4.对 API 接口的限制 每天的登录账户,请求后端 api 接口时,做调用次数限制。对后台 api 返回信息进行加密处理
通过这4层设置,就可以有效的保护数据的安全了
CentOS6.9安装软件时提示说需要Autoconf 2.64或更高的版本
[root@BobServerStation twemproxy]# autoconf
configure.ac:8: error: Autoconf version 2.64 or higher is required
configure.ac:8: the top level
autom4te: /usr/bin/m4 failed with exit status: 63查询当前版本
[root@BobServerStation twemproxy]# rpm -qf /usr/bin/autoconf
autoconf-2.63-5.1.el6.noarch卸载当前版本
[root@BobServerStation twemproxy]# rpm -e –nodeps autoconf-2.63安装最新版本
[root@BobServerStation twemproxy]# wget ftp://ftp.gnu.org/gnu/autoconf/autoconf-2.68.tar.gz[root@BobServerStation twemproxy]# tar zxvf autoconf-2.68.tar.gz[root@BobServerStation twemproxy]# cd autoconf-2.68[root@BobServerStation twemproxy]# ./configure –prefix=/usr/[root@BobServerStation twemproxy]# make && make install 查看当前版本
[root@BobServerStation autoconf-2.68]# /usr/bin/autoconf -V
autoconf (GNU Autoconf) 2.68
Copyright (C) 2010 Free Software Foundation, Inc.
License GPLv3+/Autoconf: GNU GPL version 3 or later
<http://gnu.org/licenses/gpl.html>, <http://gnu.org/licenses/exceptions.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. 至此,autoconf已升级到2.68。
ffmpeg -i "Sample.avi" -vn -ar 44100 -ac 2 -ab 128k -f mp3 "Sample.mp3"
目录查找批量修改方法:
The following command will find all mkv files that are in the current directory and in all sub-folders and extract the audio to mp3 format.
find . -type f -name "*.mkv" -exec bash -c 'FILE="$1"; ffmpeg -i "${FILE}" -vn -c:a libmp3lame -y "${FILE%.mkv}.mp3";' _ '{}' \;
The filename of the audio file will be the same as the mkv video with the correct extension. The mkv extension will be removed and replaced by the mp3 extension e.g hi.mkv will create a new file named hi.mp3
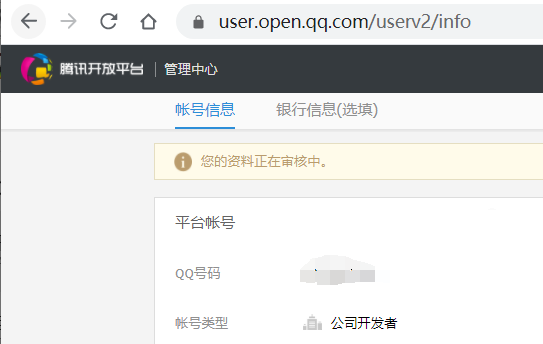
1)客户认证审核,提示“您的资料正在审核中。”–没有预估审核时间,第一的腾讯为什么做不好toB,就是这个基因问题。此外账号信息编辑及提交审核点击多次都没有反应,最新Chrome浏览器。
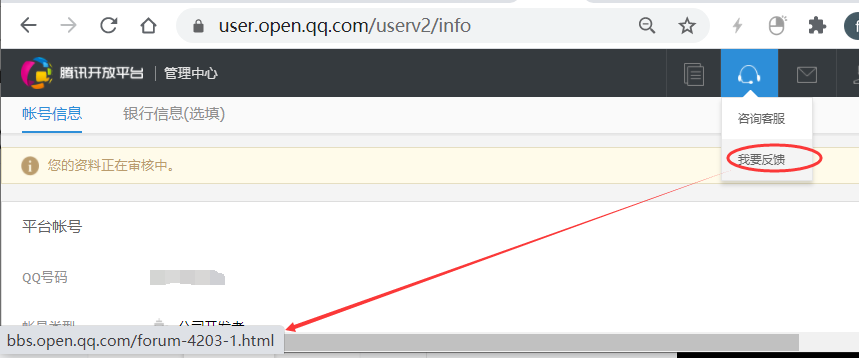
2)问题反馈留了一个打不开的链接。http://bbs.open.qq.com/forum-4203-1.html
3)产品与wifi更新文档更新不及时。