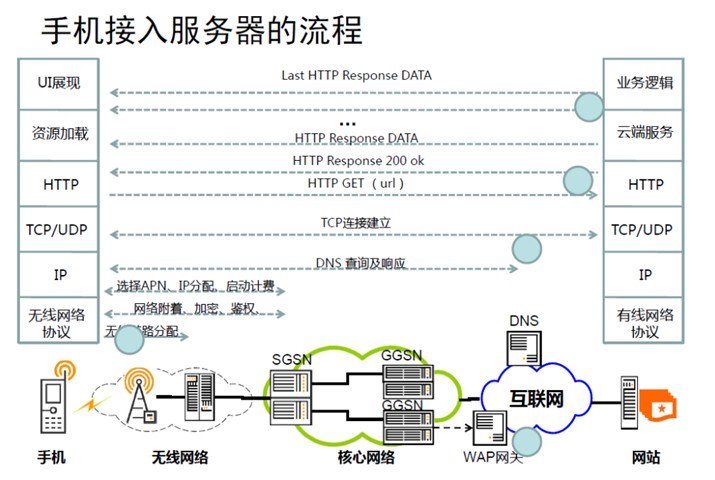
Nginx环境
a. 查看当前系统cat /etc/redhat-release
[root@nginx /]# cat /etc/redhat-release
CentOS release 6.7 (Final)
[root@nginx /]#
b. 查看系统内核uname –r
[root@nginx /]# uname -r
2.6.32-573.el6.x86_64
[root@nginx /]#
c. 安装的Nginx版本,/appliation/nginx/sbin/nginx -V
[root@nginx sbin]# ./nginx -V
nginx version: nginx/1.6.2
built by gcc 4.4.7 20120313 (Red Hat 4.4.7-16) (GCC)
TLS SNI support enabled
configure arguments: –user=nginx –group=nginx –prefix=/application/nginx1.6.2 –with-http_stub_status_module –with-http_ssl_module
[root@nginx sbin]#
location模块
Nginx location
location 指令的作用是根据用户请求的URI来执行不同的应用,URI就是根据用户请求到的网址URL进行匹配,匹配成功了进行相关的操作。
location语法
下面是官网的语法结构:
Syntax: location [ = | ~ | ~* | ^~ ] uri { … }
location @name { … }
Default: —
Context: server, location
官网解释翻译和理解
下面会结合官网原文进行解释,以下英文部分均从官网摘抄:
(翻译的不好勿喷)
Sets configuration depending on a request URI.
根据请求的URI进行配置
URI 变量是待匹配的请求字符串,
A location can either be defined by a prefix string, or by a regular expression.
Regular expressions are specified with the preceding “~*” modifier (for case-insensitive matching), or the “~” modifier (for case-sensitive matching)
一个location可以用prefix string(前缀字符串)定义,也可以通过regular expression(正则表达式来定义)
通俗的说也就是:我们可以通过使用不同的前缀,表达不同的含义,对于不同的前缀可以分为两大类:普通location和正则location
符号:”~”表示uri包含正则,并且区分大小写
符号:“~*”表示uri包含正则,但不区分大小写
注意:如果你的uri用正则,则你的正则前面必须添加~或者~*,之前我在这里存在误区,以为可以不加~或者~*
To find location matching a given request, nginx first checks locations defined using the prefix strings (prefix locations). Among them, the location with the longest matching prefix is selected and remembered. Then regular expressions are checked, in the order of their appearance in the configuration file. The search of regular expressions terminates on the first match, and the corresponding configuration is used. If no match with a regular expression is found then the configuration of the prefix location remembered earlier is used.
Nginx服务器会首先会检查多个location中是否有普通的uri匹配,如果有多个匹配,会先记住匹配度最高的那个。然后再检查正则匹配,这里切记正则匹配是有顺序的,从上到下依次匹配,一旦匹配成功,则结束检查,并就会使用这个location块处理此请求。如果正则匹配全部失败,就会使用刚才记录普通uri匹配度最高的那个location块处理此请求。
If the longest matching prefix location has the “^~” modifier then regular expressions are not checked.
当普通匹配的最长前缀匹配有符号“^~”的时候,就不会在匹配正则
直接使用当前匹配的这个location块处理此请求
Also, using the “=” modifier it is possible to define an exact match of URI and location. If an exact match is found, the search terminates. For example, if a “/” request happens frequently, defining “location = /” will speed up the processing of these requests, as search terminates right after the first comparison. Such a location cannot obviously contain nested locations.
使用符号“=”修饰符可以定义一个精确匹配的URI和位置,如果找到了一个精确的匹配,则搜索终止,例如,如果一个”/”请求频繁发生,定义“location =/”将加快这些请求的处理,一旦精确匹配只有就结束,这样的location显然不能包含嵌套location
这里我们说一下location / {} 和location =/ {}的区别:
“location / {}”是普通的最大前缀匹配,任何的uri肯定是以“/”开头,所以location / {} 可以说是默认匹配,当其他都不匹配了,则匹配默认匹配
根据上述官网内容进行总结
a. ”=”用于普通uri前,要求精确匹配,如果匹配成功,则停止搜索并用当前location处理此请求
b. ”~” 表示uri包含正则,并且区分大小写
c. “~*”表示uri包含正则,但不区分大小写
d. ”^~”表示在普通uri前要求Nginx服务器找到普通uri匹配度最高的那个location后,立即处理此请求,并不再进行正则匹配
e. ”^~”和“=”都可以阻止继续匹配正则location两者的区别:“^~”依然遵守最大前缀原则,然后“=”是需要严格匹配
关于location网上的一些误解
location 的匹配顺序是“先匹配正则,再匹配普通”
这是一个错误的结论,从上面官网的文章中我们可以知道:
先匹配普通uri,然后记住匹配度最高的那个(官网原话:To find location matching a given request, nginx first checks locations defined using the prefix strings (prefix locations). Among them, the location with the longest matching prefix is selected and remembered.)然后匹配正则,如果正则匹配则结束查找,如果正则不匹配,则匹配之前普通匹配中匹配度最高的那个将执行该请求(官网原话:Then regular expressions are checked, in the order of their appearance in the configuration file. The search of regular expressions terminates on the first match, and the corresponding configuration is used. If no match with a regular expression is found then the configuration of the prefix location remembered earlier is used.)
所以:location 的匹配顺序是“先匹配正则,再匹配普通” 这句话肯定是错误的,况且这里并没有包含”^~”和“=”
location 的执行逻辑跟 location 的编辑顺序无关。
这也是一种错误的理解,我们根据上述内容可以知道:
如果是普通uri 匹配,这个时候是没有顺序的,但是正则匹配则是有顺序的,是从上到下依次匹配,一旦有匹配成功,则停止后面的匹配。
那么顺序到底是怎么匹配呢?
我画了一个location匹配的逻辑图便于理解匹配的顺序规则

通过实验来验证出结果
对www.conf配置如下:
[root@nginx extra]# cat www.conf
server {
listen 80;
server_name www.zhaofan.com;
access_log logs/access_www.log;
root html/www;
location / {
return 401;
}
location = / {
return 402;
}
location /documents/ {
return 403;
}
location ^~ /images/ {
return 404;
}
location ~* \.(gif|jpg|jpeg)$ {
return 500;
}
}
[root@nginx extra]#
注意:
location ~* \.(gif|jpg|jpeg)$ {
return 500;
这个部分$前面不能有空格,否则会提示如下错误:
[root@nginx extra]# ../../sbin/nginx -s reload
nginx: [emerg] invalid location modifier “~*\.(gif|jpg|jpeg)” in /application/nginx1.6.2/conf/extra/www.conf:19
如果$后面没有空格,则会提示如下错误:
[root@nginx extra]# ../../sbin/nginx -s reload
nginx: [emerg] directive “location” has no opening “{” in /application/nginx1.6.2/conf/extra/www.conf:23
这些都是细节问题,一定要注意
实验一:登录nginx网站,我这里的直接打开:http://192.168.8.105/

可以看出这里是精确匹配
location = / {
return 402;
}
实验二:打开http://192.168.8.105/aaa/

这里可以看出因为都不匹配,所以最后匹配了location / {}
location / {
return 401;
}
实验三:打开http://192.168.8.105/1.gif

这里可以看出是匹配了正则
location ~* \.(gif|jpg|jpeg)$ {
return 500;
}
实验四:打开http://192.168.8.105/aaa/1.gif

这里依然是匹配正则
location ~* \.(gif|jpg|jpeg)$ {
return 500;
}
实验五:打开http://192.168.8.105/images/1.gif

location / {
return 401;
}
location = / {
return 402;
}
location /document/ {
return 403;
}
location ^~ /images/ {
return 404;
}
location ~* \.(gif|jpg|jpeg)$ {
return 500;
}
这里通过配置把实验三和实验四的对比就可以看出来因为普通匹配里有“^~”,并且匹配到了images,所以这个就是不进行正则匹配
location ^~ /images/ {
return 404;
}
实验六:“^~”遵守最大前缀原则
配置如下:
location / {
return 401;
}
location = / {
return 402;
}
location = /document/ {
return 403;
}
location ^~ /images/ {
return 404;
}
location /images/1/ {
return 501;
}
location ~* \.(gif|jpg|jpeg)$ {
return 500;
}
还是关注标红的地方,这个时候我们登陆:http://192.168.1.19/images/
结果如下:

从这里可以看出匹配了:
location ^~ /images/ {
return 404;
}
但是如果我们登陆:http://192.168.1.19/images/1/
结果如下;

这里匹配了:
location /images/1/ {
return 501;
}
从这里我们可以看出“^~”遵守最大匹配原则。
实验七:当最长匹配和精确匹配相同时
配置如下:
location / {
return 401;
}
location = / {
return 402;
}
location = /document/ {
return 403;
}
location ^~ /images/ {
return 404;
}
location /images/1/ {
return 501;
}
location = /images/1/ {
return 502;
}
location ~* \.(gif|jpg|jpeg)$ {
return 500;
}
登陆:http://192.168.1.19/images/1/
结果如下:

但是如果这个时候登陆:http://192.168.1.19/images/1/aaa/
结果如下:

从这里我们可以看出当精确匹配和最长匹配相同时,匹配的是精确匹配。
不在过多的做实验,根据上面的逻辑图应该可以解决碰到的问题了所有的努力都值得期许,每一份梦想都应该灌溉!